
Data Science Experience - Data Sciences
Machine Learning to Detect Anomalies in DoD Contracts
MAJ Nick Lee
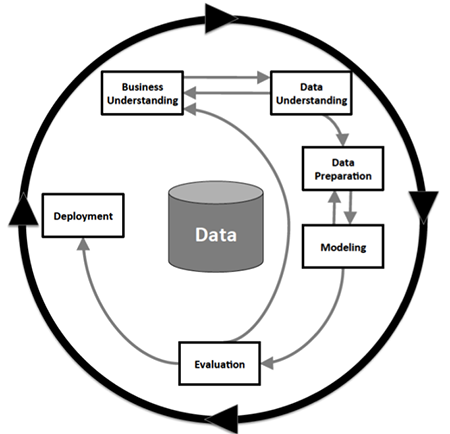 Our study of the USASpending data demonstrates the identification of important variables related to best spending practices can be used to identify trends and contracts that stand out as unusual. We show anomalies in multiple ways: (1) visual comparison of averages; (2) outlier identification of spending patterns, (3) secondary testing for values, (4) a more in-depth analysis of an awarding office, and (5) an application to view multiple results at once.
Our study of the USASpending data demonstrates the identification of important variables related to best spending practices can be used to identify trends and contracts that stand out as unusual. We show anomalies in multiple ways: (1) visual comparison of averages; (2) outlier identification of spending patterns, (3) secondary testing for values, (4) a more in-depth analysis of an awarding office, and (5) an application to view multiple results at once.
Anomaly Detection Approaches
MAJ Smith & Dr. John Alt
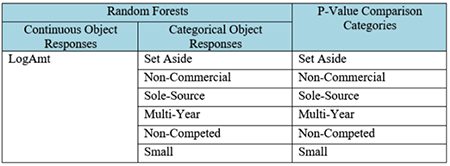
Initial anomaly detection methods identified ~1,000 anomalous records out of 1.45 million, reducing the records for an analyst to explore manually by over 99%.
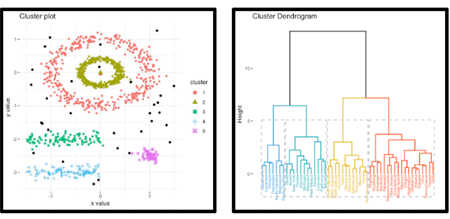
Clustering--a technique used to put objects into groups that are somehow similar in characteristics.
Clustering Methods: Kmodes, Hierarchical Agglomerative Clustering (HAC), Partition Around Medoids (PAM), Randome Forests (supervised and unsupervised), PAM with Dissimilarity Matrix (Daisy)
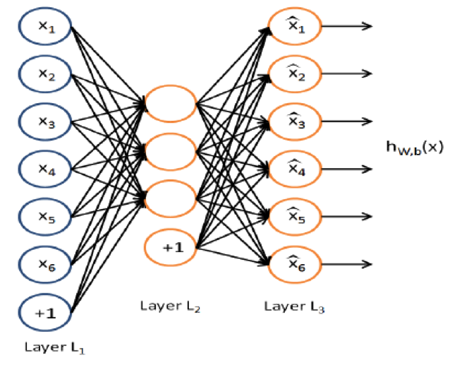
Neural Network Autoencoder--an unsupervised learning algorithm that applies backpropagation, setting the target values to be equal to the inputs.
Demographic Prediction
LCDR Jeff Good & MAJ Gabe Samudio
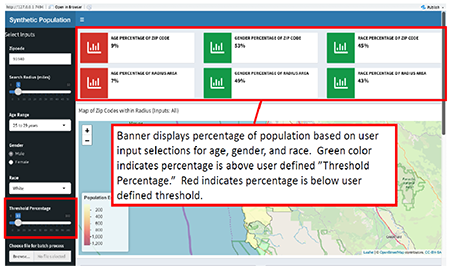
USAREC recruiters regularly receive partial demographic information from potential recruits. Recruiters and associated professionals need a rapid method to predict unknown demographic and financial information to enhance decision making by reducing the uncertainty of missing information.
Moneyball for Maintainers
MAJ Chris Arnold & MAJ Dan Hudalla
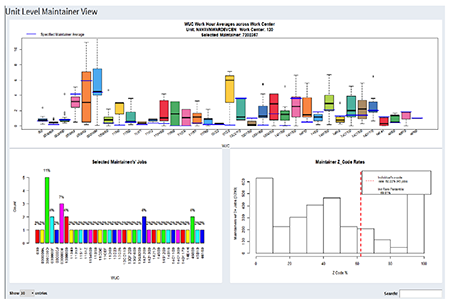
Analytics have revolutionized many industries concerned with individual and team performance. Naval Air Systems Command (NAVAIR) seeks an analytic approach to improve maintenance by using maintenance data to gain insights about maintainer performance, end item reliability, and maintenance efficiency.
NAVAIR is interested in a “Moneyball for Maintenance” approach that allows leaders to clearly see and maximize the performance metrics of their maintainers for the good of the organization.
Analysis of Large Text Data Corpus
Major Joe Moeller, Captain Chris Teska, & Lieutenant Cang Pham
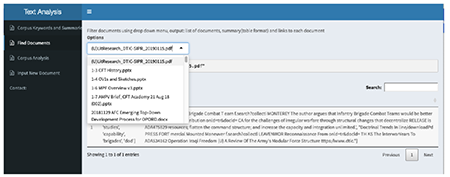
Develop a process to rapidly extract text data in order to classify documents and identify key topics, issues, or questions.
Currently, much time and effort is needed to analyze documents manually for inclusion into senior level “Decision Packages”. Personnel must organize data into one of three categories: Challenges, Opportunities, or Issues. These categories are then aligned with the current priorities incorporated into AFC Task 5.
Text Summarization
- Fully connected graph of sentences
- Based on Cosine Similarity
- PageRank Algorithm on graph
Latent Dirichlet Allocation
- Algorithmically identifies topics
- Assesses document – topic fit
- Allow association with multiple topics
- Keywords associated with each topic
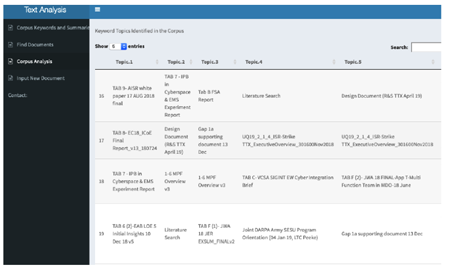
- Easy access to document keywords and summaries
- Topic Modelling ranks each document by topic assignment
- Keywords for each topic are identified and easily searched
Recent "Data Science" Thesis work:

Classifying vessels operating in the South China Sea by origin with the Automatic Identification System
be possible. A special thank you to my husband Danny, my family, and my friends who all supported me during my time as a graduate student. v THIS PAGE INTENTIONALLY LEFT BLANK vi I. INTRODUCTION Many companies and organizations are becoming increasingly interested in data...



















